 Picture courtsey: Priscilla Du Preez on Unsplash
Picture courtsey: Priscilla Du Preez on Unsplash
RNN vs LSTM vs Transformer
With the advent of data science, NLP researchers started modelling languages to better understand the context of the sentences for different NLP tasks.
Recurrent Neural Networks (RNN)
Let’s start with the most “basic” approach- Feed-Forward Networks (FFN). FFN would take the whole sentence as input and would try to model probability to each word in the sentence. But since the output in a FF layer is unaffected by the neurons in the same layers, the hierarchy of the textual/ grammatical information that the input sentence possesses gets lost. To combat that, RNNs were introduced with the idea that a feedback loop in a neuron could help the network retain the information of its previous state. That’s why word by word inputs are fed in RNNs instead of a whole sentence.
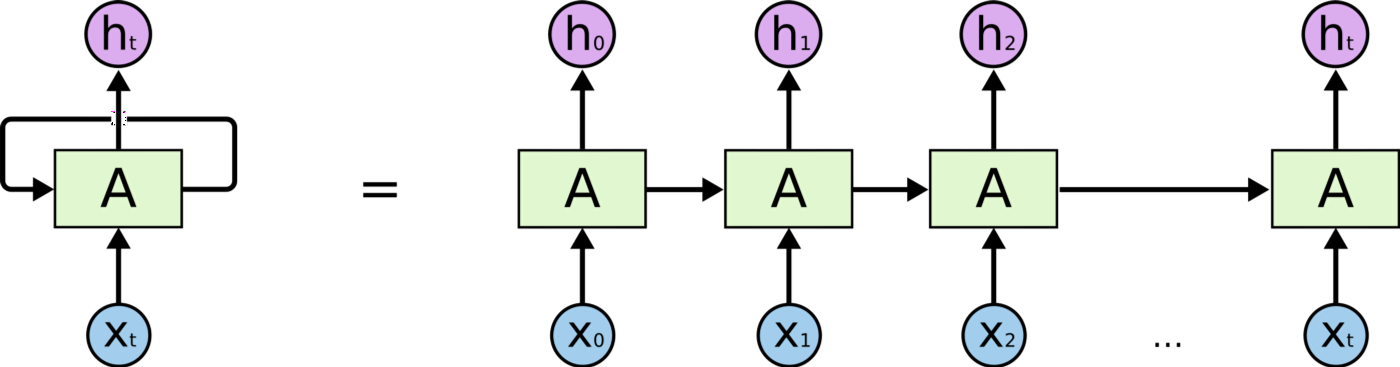 Picture courtsey: Understanding LSTMs
Picture courtsey: Understanding LSTMs
A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor
The information holding capability of RNN helps in numerous NLP tasks, but soon an inherent problem in the practical design of these networks surfaced. In shorter sentences like “The Sun rises in the east”, where the required information is not cluttered and the required context is near RNNs performs well but in longer sentences like “I grew up in France... I speak fluent French”, the prediction results are terrible. By nearby words, RNNs can suggest that the answer has to be of type "language" but the context of the country (France) gets lost because of cluttering of information with other text. Thus, RNNs perform poorly in “long term dependencies” along with the problem of vanishing gradients during backpropagation.
Long Short-Term Memory (LSTM)
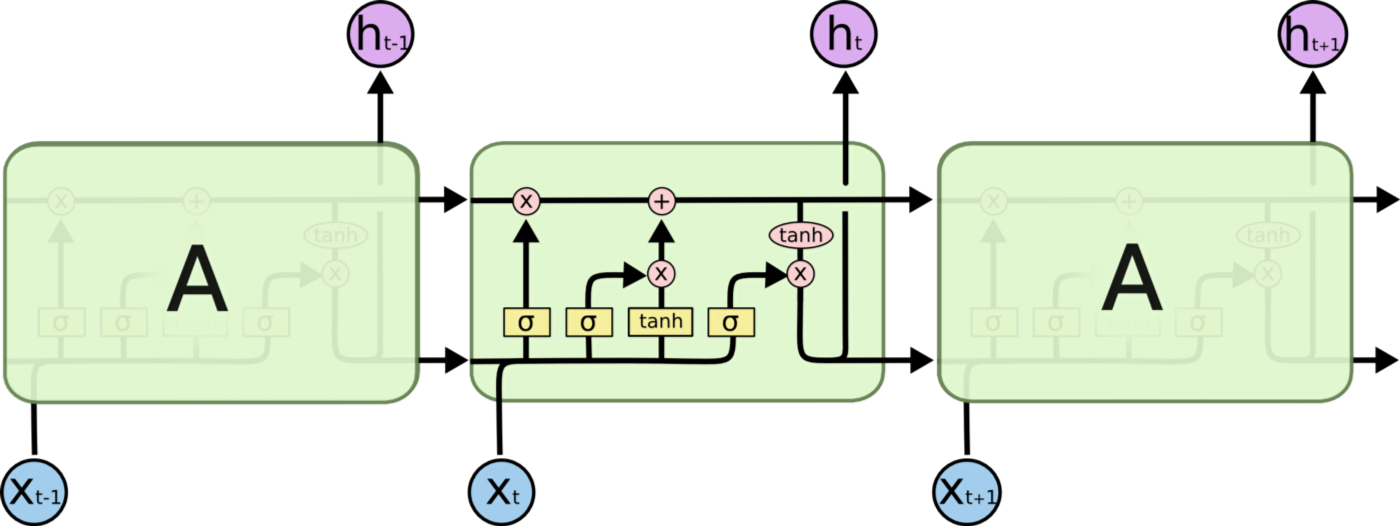 Picture courtsey: Understanding LSTMs
Picture courtsey: Understanding LSTMs
An LSTM network, notice the sigmoid and tanh gates inside the cell
To add “long term dependencies” and go away with the issues of gradients, LSTMs were introduced. They are RNNs with additional gates to “carefully” regulate the amount of information to be passed on the next cell. This regulation of information across cells instantly solved the issue of vanishing gradients and “long term dependencies” in RNNs but increased the computational time.

Evident from the above image, it is observed that humans do not read text sequentially but interpret characters, words and sentences as groups. Thus came the idea of “attention” in NLP, which says that focus on what you want to look at and forget the rest. Several attempts were made and are being made in improving the performance of LSTMs with attention but the model that stood out of the rest was Sequence-to-Sequence model (Seq2Seq) coupled with attention or technically known as “transformer”.
Transformer
Seq2Seq models were originally developed with LSTMs for language translation. They comprise two stages: an encoder and decoder stage. The encoder stage converts the original language (input) into a common higher-dimensional latent space which acts as an input for the decoder stage. The decoder model then sequentially interprets its input along with previous decoded word to give the next translated word (output).
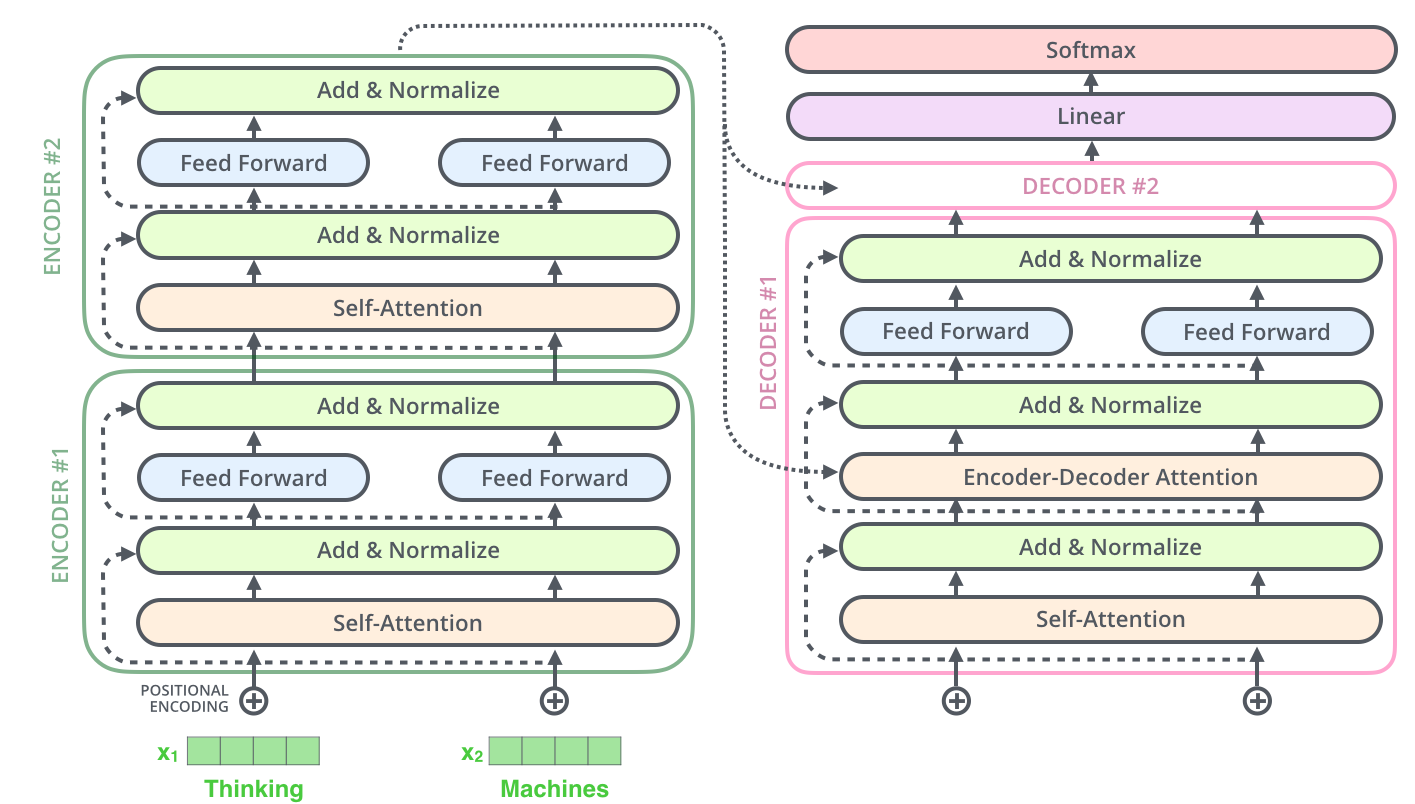 Picture courtsey: Illustrated Transformer
Picture courtsey: Illustrated Transformer
A Transformer of 2 stacked encoders and decoders, notice the positional embeddings and absence of any RNN cell
Surprisingly, Transformers do not imply any RNN/ LSTM in their encoder-decoder implementation instead, they use a Self-attention layer followed by an FFN layer. Now you may ask, what happened to our need to memorise the context which was essentially the reason to introduce RNN? Transformers’ encoding stage does not take the input in time sequence (i.e, word by word) but as a whole sentence. The self-attention layer gets the context of relevant nearby words for the focus-word by gaining the hierarchal information of an input text. Now if you are a very inquisitive reader you may ask, Does that mean that transformers do not differentiate between jumbled sentences? To solve that, transformer architecture adds positional embeddings to the input sequence. These positional embeddings follow a specific pattern that the model learns, which helps it determine the position of each word or the distance between different words in the sequence. In the original paper, sine and cosine functions of different frequencies are used with the intuition of drawing a parallel with brain waves and neural oscillations. The Transformer model later gave BERT, sometimes referred to as the ImageNet moment of NLP which I will discuss in some later post.
P.S. In this article, I have mostly discussed the intuition behind each model. I have specifically not discussed individual components of RNNs, LSTMs and Transformers in-depth as there are existing blog posts which lucidly explain their working in great detail.
Stay Well, Stay Safe!
Further reading
[RNN]: http://karpathy.github.io/2015/05/21/rnn-effectiveness/[LSTM]: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[Transformer]: http://jalammar.github.io/illustrated-transformer/
References
1. https://towardsdatascience.com/the-fall-of-rnn-lstm-2d1594c74ce02. https://medium.com/inside-machine-learning/what-is-a-transformer-d07dd1fbec04