 Picture courtsey: Pexels
Picture courtsey: Pexels
UbiComp 2020, an A* conference on Ubiquitous and Pervasive Wearable technologies ended with a beautiful surprise. Never in my wildest dreams, had I thought that my first paper would bag the Best Paper award (1 out of 121 papers)! Consequently, I felt that I should cover my paper in Bitshots giving a hand-waving explanation of the system and how it was achieved. So, let’s start the paper review of RFID Tattoo: A Wireless Platform for Speech Recognition by Jingxian Wang et al.
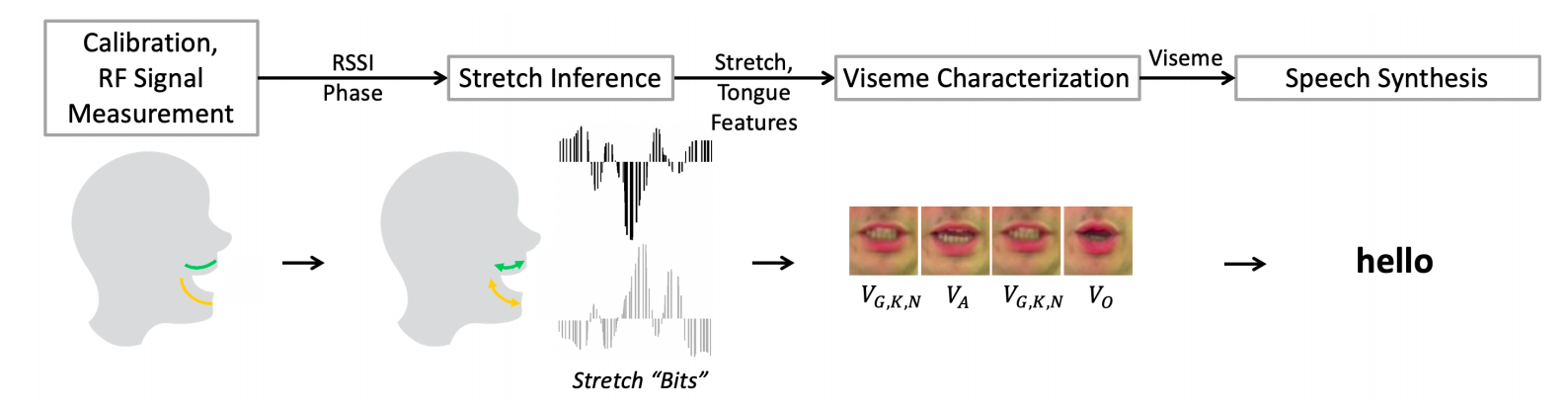 Picture courtsey: RFID Tattoo paper
Picture courtsey: RFID Tattoo paper
Pipeline of RFID Tattoo from tag stretch to speech synthesis
The System
RFID Tattoo is an RFID based solution for lip-reading, which due to its inherent design overcomes many potential problems in existing solutions of speech and vision. Camera-based visual solutions of real-time lip reading have shown to prove good performance, but they render useless when there is low lighting or reflection from a user’s face. Similarly, Audio-based speech solution only works when a user can produce some sound and will still fail in a noisy environment.
RFID Tattoos are wafer-thin sticky tattoos attached around the user’s mouth. Since RFID tags are passive and do not require any external energy source, the system could work in adverse conditions with minimum overhead. The stretch of the Tattoos would make signal variations to a portable RFID reader who would recognise the various facial gestures to distinct classes of sound. A detailed user study with 10 users reveals 86% accuracy in reconstructing the top-100 words in the English language.

RFID Tattoos in action
Getting the signal
Stretching an RFID tag changes its antenna’s electrical length and therefore, its resonant frequency shifts towards lower frequencies. A stretch of 1mm would shift the resonant frequency by 8MHz. Considering we are working only in the 902-928MHz range, this would make the resonant frequency fall out of the available bandwidth. To circumvent this problem, RFTattoo finds the resonant frequency by relying on multiple co-located tags instead of numerous widely separated frequencies to obtain stretch. Specifically, all the tags would resonate at the 900 ISM band, but only when pulled to specific values of stretch. let t_1,...,t_n be designed to resonate at maximum power when stretched to values s_1,...,s_n where n is the possible resonant frequency values in the band.
Let P(t_i) denote the power of the signal received from tag t_i . Then the expected value of stretch s can be directly interpolated from the power of each tag as:
\begin{equation}
s = \sum_i s_i \frac{P(t_i)}{\sum_j P(t_j)}
\end{equation}
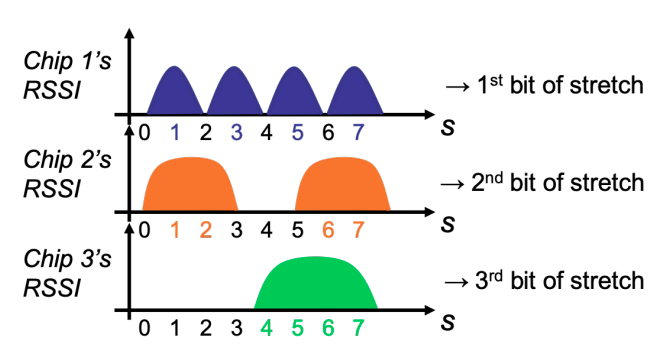
Picture and caption courtsey: RFID Tattoo paper
The ith chip on an RFTattoo tag responds with a maximum signal power when the ith bit of s is one, where s is tag stretch. For example, Chip 3 responds when the 3rd bit of stretch is on which corresponds to the possible stretch of 4, 5, 6, 7 in the figure
But, such a solution would work if it was working in a continuous domain, i.e. n needs to be large, which is unfeasible considering the limited number of tags that could be worn. RFTattoo develops a sub-optimal solution that would require a sub-linear number of tags k ~ O(log n) to sample n discrete resonant frequencies. It designs k tags each designed to always resonate on a set of multiple frequencies. In particular, the j th tag is designed to resonate at all frequencies where the jth bit of the resonant frequency index f is one. In effect, this ensures that by simply reading off the power of the k = ⌈log n⌉ tags, one can infer the true stretch of all tags. Mathematically, the index of the resonant frequency among n possible values can be written as:
\begin{equation}
f = \sum^k_{i=1} 2^{i-1}x_i
\end{equation}
Getting speech from the signals
First, the tag signals were characterised into specific visemes, a unit of visual speech. Viseme represents the shape of the face when the user attempts to speak a particular phoneme. The most suited machine learning model for this task was the Random Forest model. Deep learning techniques could not be employed due to the paucity of sensor data. Similarly, for word classification from continuous timesteps of tag signals, the same Random Forest model was used. Predicting a word alone was itself difficult due to lack of context. Though, a good proportion of words can be accurately classified since the utterance of a word generates a much richer time and frequency response owing to the longer time series containing instances of multiple stretches. Overall, RFTattos achieved an accuracy of 86% over a vocabulary of the top 100 English words averaged over 10 users.
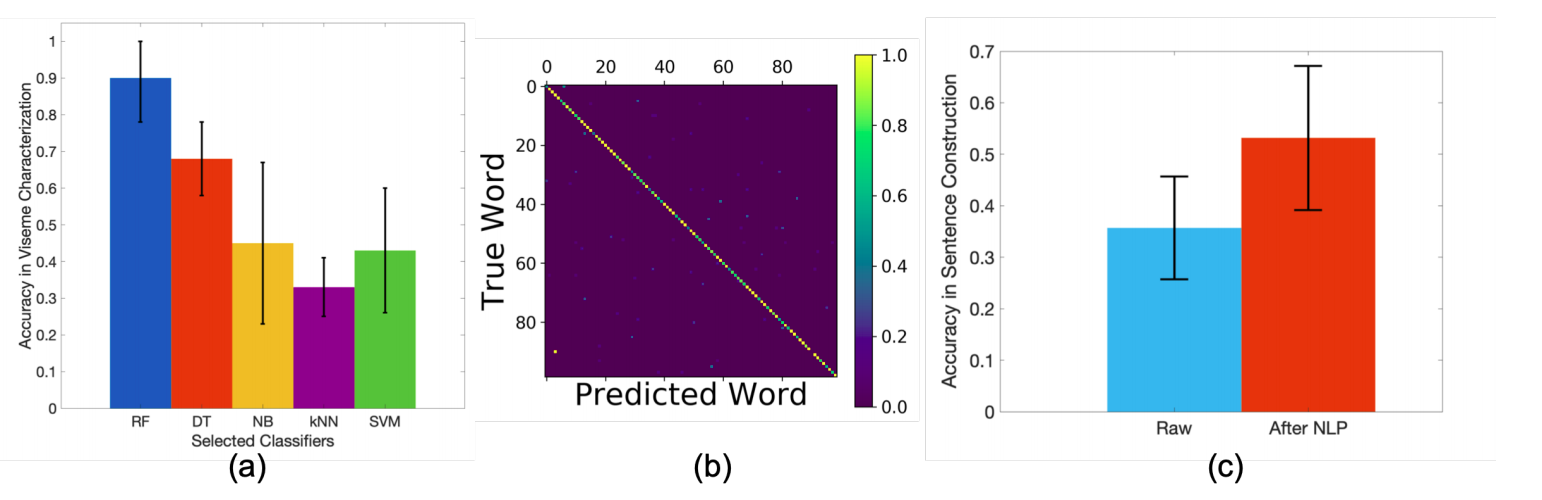
Picture courtsey: RFID Tattoo paper
a) Viseme classification accuracy wrt Random Forest, Decision Tree, Naive Bayes, kNN and SVM b) Confusion matrix for top-100 words classification c) Accuracy in sentence construction (not covered in blogpost)
In short...
RFID Tattoo provides an out of the box solution for dealing with speech dysphonia by using a mix of many novel ideas. That said, the system still has some limitations which can hopefully be overcome in its future iterations. I would request all the readers to check out the original paper as well since it covers a more in-depth discussion of all the above points along with many other caveats that have been left out to maintain quick readability of the blog.
Until then, Stay Well! Stay Safe!