 Picture courtsey: Katrina Wright on Unsplash
Picture courtsey: Katrina Wright on Unsplash
Last year, a debate sprang across the NLP community when Google released XLNet, a model that improved upon BERT on 20 tasks! But some people were sceptical of the performance comparison as the two models were trained on two datasets of very different size. It was hard to tell whether the increase in performance is due to more data or novel architectural design on XLNet. The debate finally settled when Facebook released RoBERTa, retrained BERT with insanely more data, the result being that it outperformed XLNet showing that the increment in performance was due to more data and not the architecture itself [1]. Does this bolster the claim that more the data, better is the model?
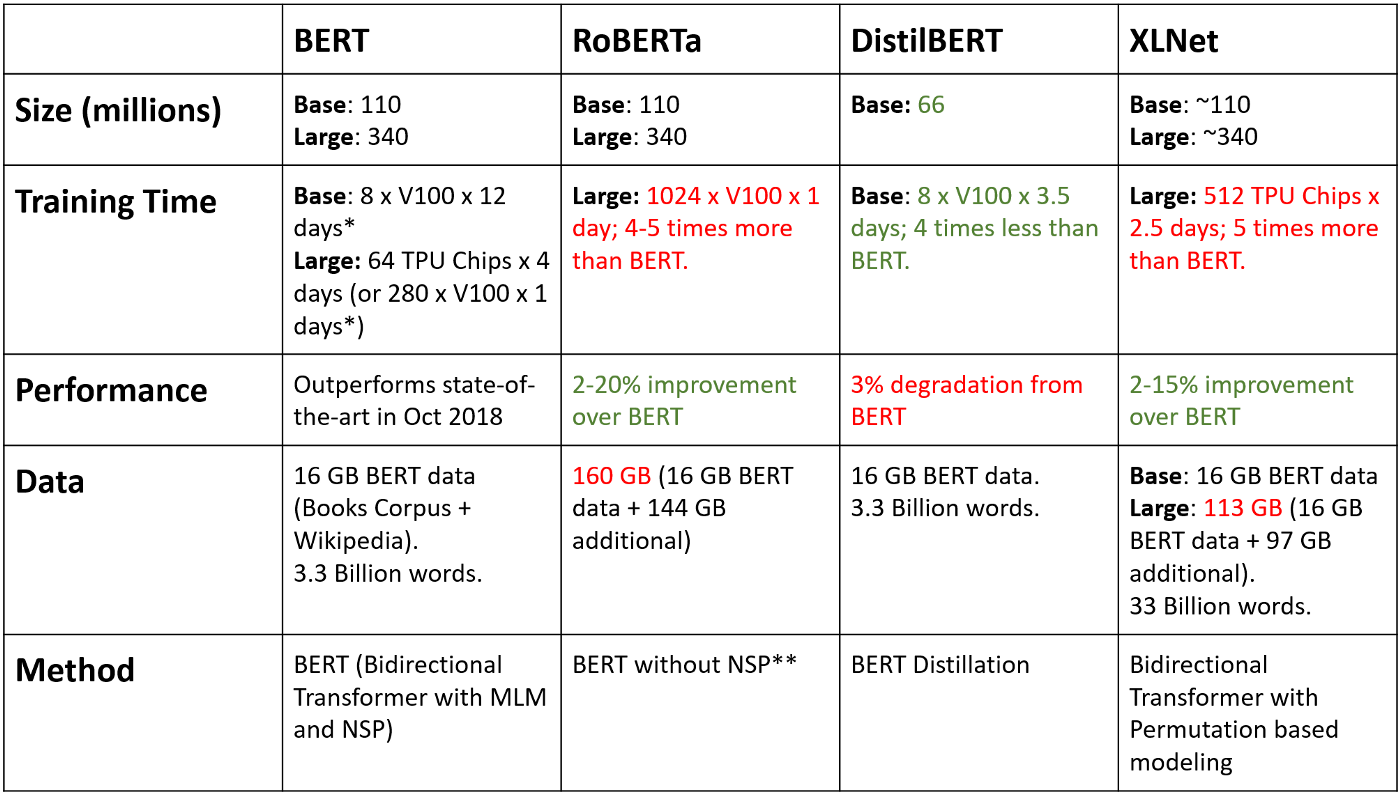 Picture courtsey: BERT, RoBERTa, DistilBERT, XLNet — which one to use?
Picture courtsey: BERT, RoBERTa, DistilBERT, XLNet — which one to use?
Figure showing the dataset sizes of BERT, XLNet and RoBERTa
In January 2020, researchers from OpenAI empirically identified trends between the performance of Transformer model size (excluding the embeddings layer) and dataset size in comparison with limited computational power. Some of their salient claims are: [2]
- The performance has a power-law relationship with each of the scale factor (model, dataset and compute) when not limited by other two, with trends spanning more than six orders of magnitude. This means we can predict the model performance without even conducting a full 2.5-3 days run! A big *whoosh* by planet Earth!
- Overfitting can be avoided if model size (N) and dataset size (D) is increased in N^0.74 : D ratio, i.e, every time we increase N by 8x increase the dataset by 5x to avoid overfitting
- Transfer learning performance increases with the size of training validation set with a roughly constant offset in loss
- Large models are sample efficient than smaller models, reaching the same level of performance with fewer optimisation steps and fewer data points
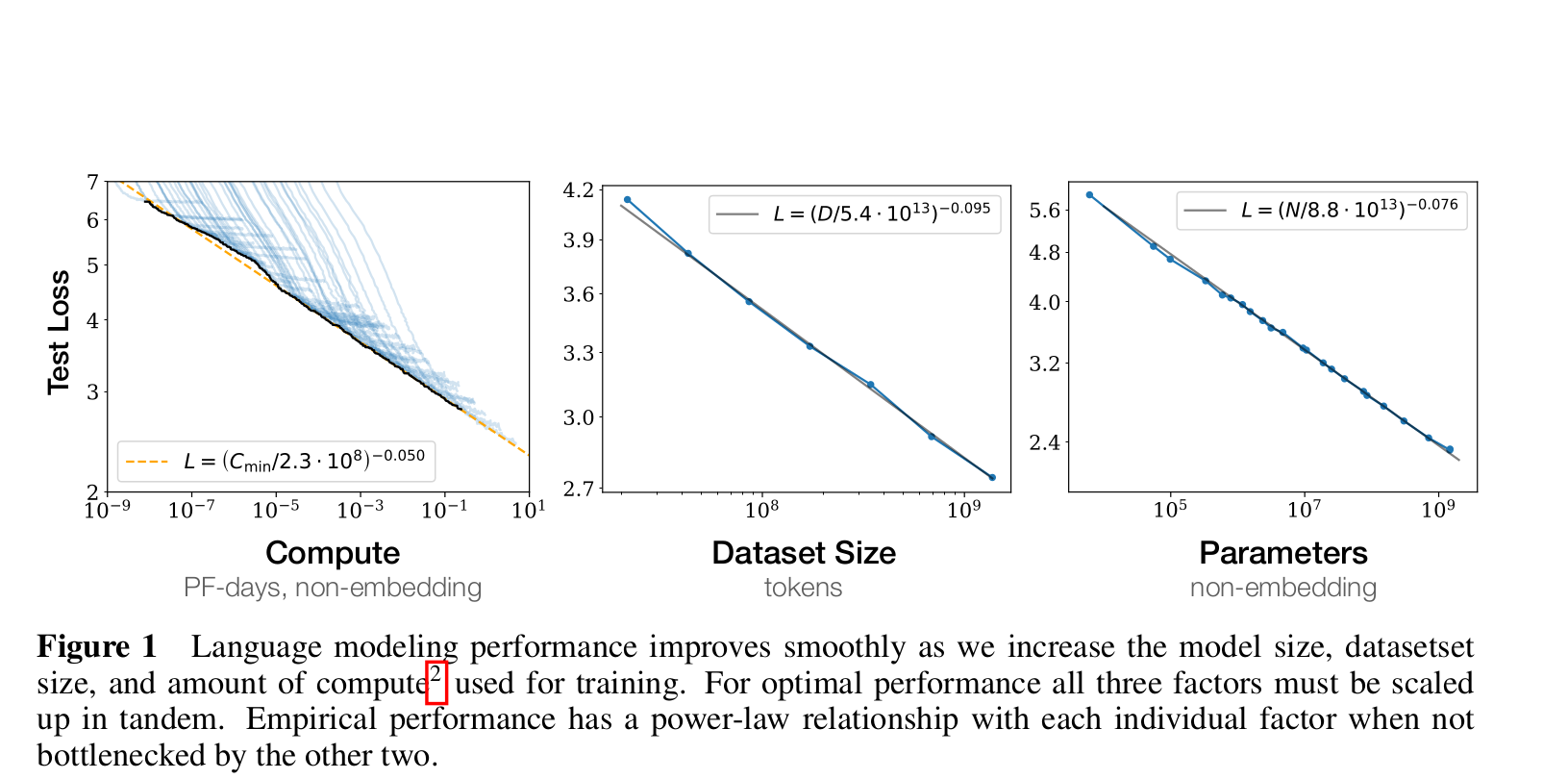
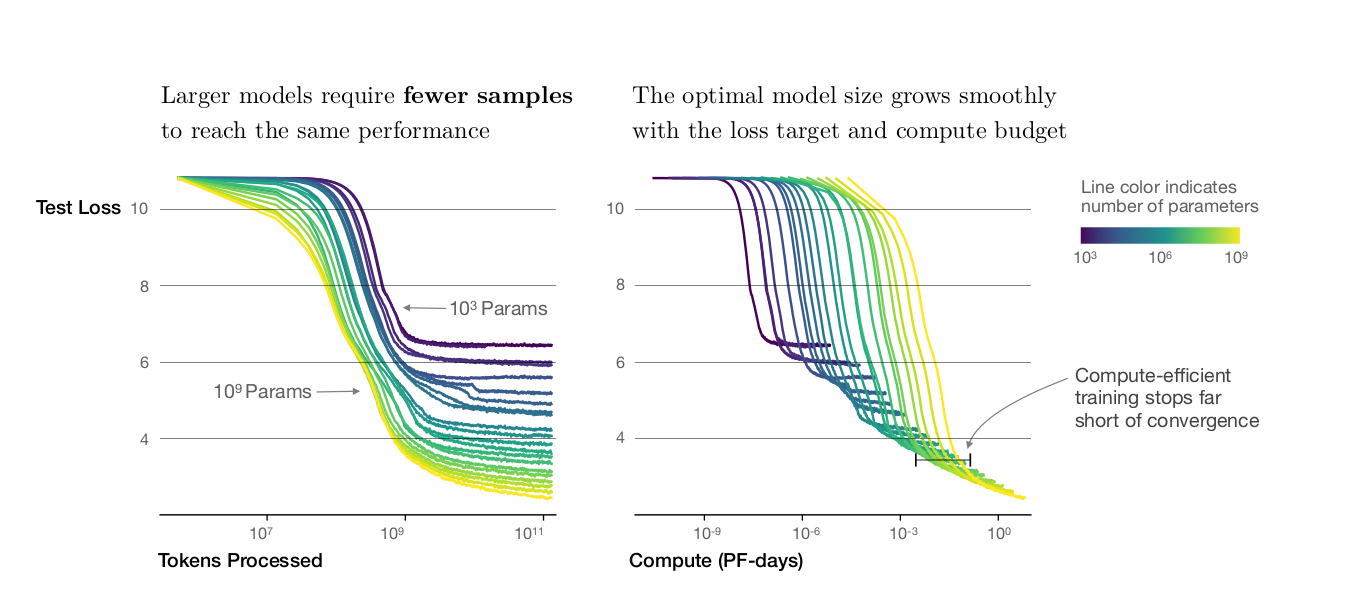 Picture courtsey: Scaling Laws for Neural Language Models
Picture courtsey: Scaling Laws for Neural Language Models
Their empirical data certainly points towards the bigger is better narrative in NLP
This increase in the size of language models is making it increasingly difficult for budding researchers (*cough* like me :P) to contribute to this beautiful field. An Israeli research company AI21 labs looked for the expected cost of training NLP models and the factors involved. The team compared three different-sized BERT models on the 15 GB Wikipedia and Book corpora, evaluating both the cost of a single training run and typical, fully-loaded model cost. The team estimated fully-loaded cost to include hyperparameter tuning and multiple runs for each setting: [3,4]
- $2.5k — $50k (110 million parameter model)
- $10k — $200k (340 million parameter model)
- $80k — $1.6m (1.5 billion parameter model)
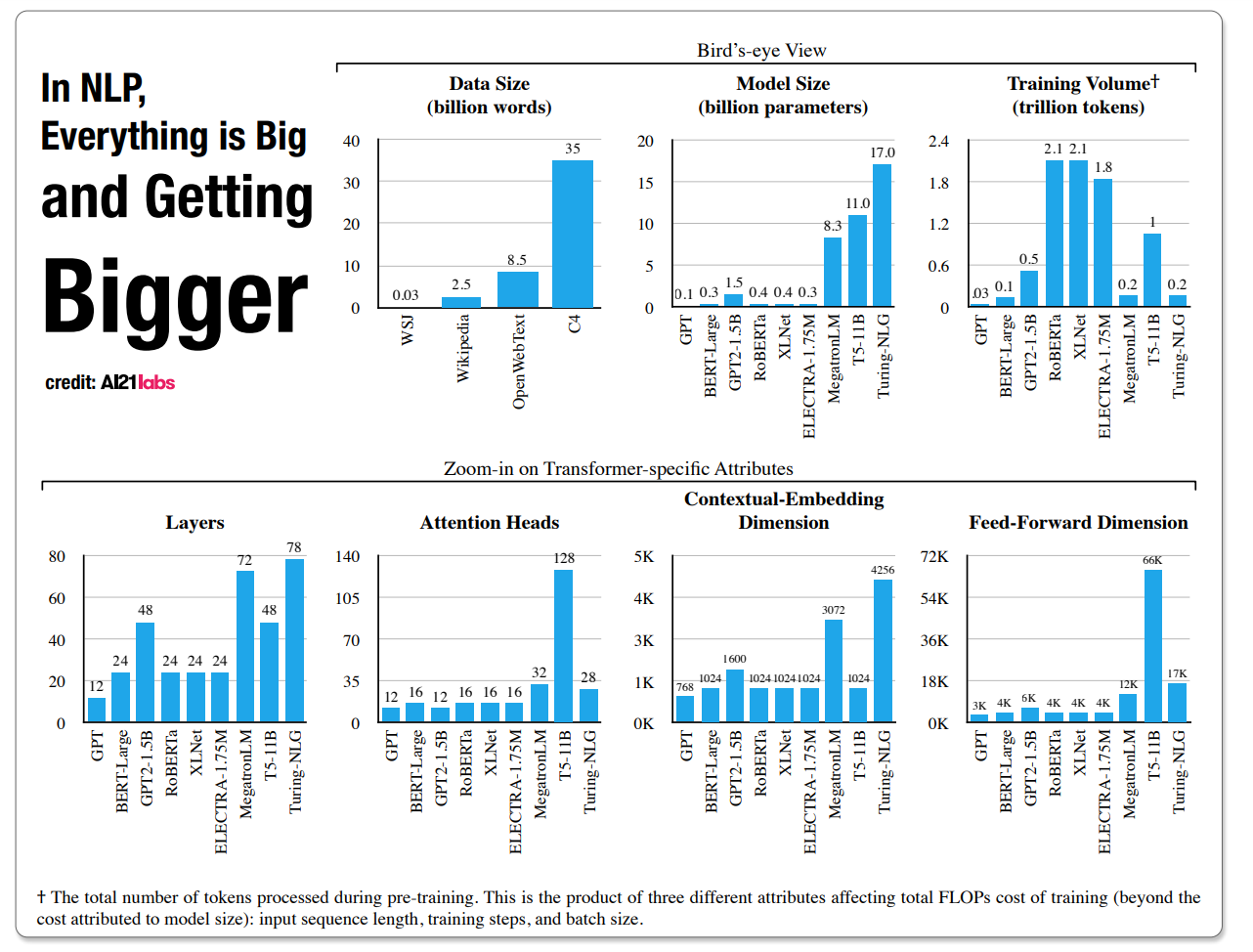 Picture courtsey: The Cost of Training NLP Models
Picture courtsey: The Cost of Training NLP Models
Notice the words "billion" and "trillion" in the graph
Training costs can vary drastically due to different technical parameters, climbing up to the US $1.3 million for a single run when training Google’s 11 billion parameter Text-to-Text Transfer Transformer (T5) neural network model variant. A project that might require several runs could see total training costs hit the jaw-dropping US $10 million! [3]
So, what's next? I believe that the bigger is better narrative will be in play until it plateaus and sooner or later the results will also depend on the brain (novel architectures) rather than only brawn (data).
Until then, Stay Well! Stay Safe!
References
- BERT-RoBERTa-distilBERT-XLNet which one to use
- Paper: Scaling Laws for Neural Language Models
- AI21 Labs Asks: How Much Does It Cost to Train NLP Models?
- Paper: The Cost of Training NLP Models: A Concise Overview