 Picture courtsey: cottonbro from Pexels
Picture courtsey: cottonbro from Pexels
The language models have been the torchbearers of SOTA in NLP from the past three years, which honestly, in deep learning years is equivalent to a decade! Pre-trained language texts model has shown us time and again that they are better capable of understanding the structure of text than any other supervised approach and certainly than traditional RNNs (*poof*).
This paper implements the same idea of a language model to images. Though there have been numerous instances of such occurrences before, this model stands out in its peculiar pixel by pixel generation approach which resembles quite a lot with text. Moreover, their insights on the linear probe are something to be cognizant of for budding researchers. So let’s start the review of ICML2020, honourable mention paper Generative Pretraining from Pixels by Mark Chen et al.
 Picture courtsey: iGPT paper
Picture courtsey: iGPT paper
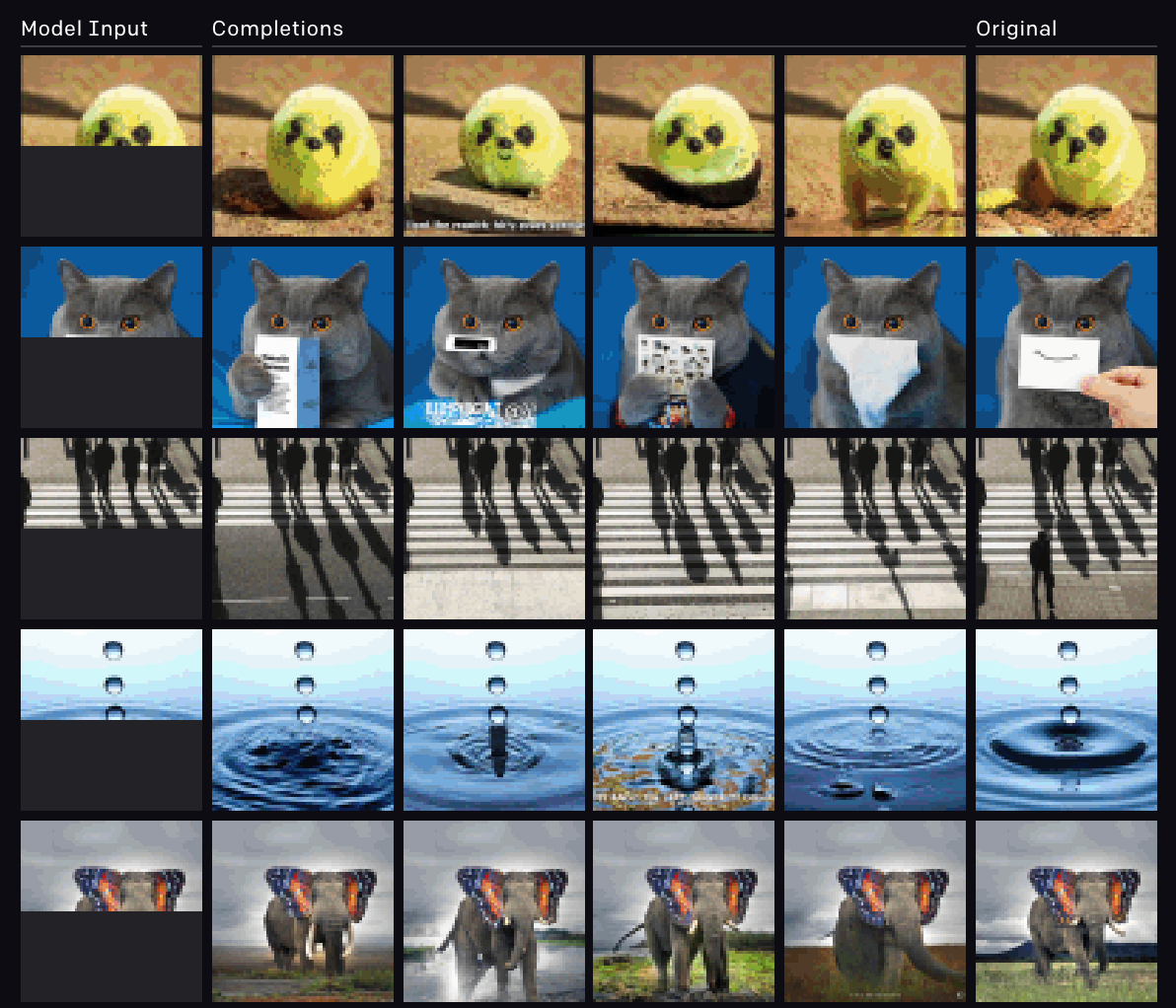
Model-generated completions of human-provided half-images. The remaining halves were sampled with temperature 1 and without tricks like beam search or nucleus sampling
Difference in approach than Pre-trained models
Classical pre-trained ImageNet models, like Resnet, VGG etc. were trained on the classification tasks. On the contrary, this paper’s model termed iGPT (image-GPT) is pre-trained on image generation task and later fine-tuned on the classification task to flex its capability.
Architecture
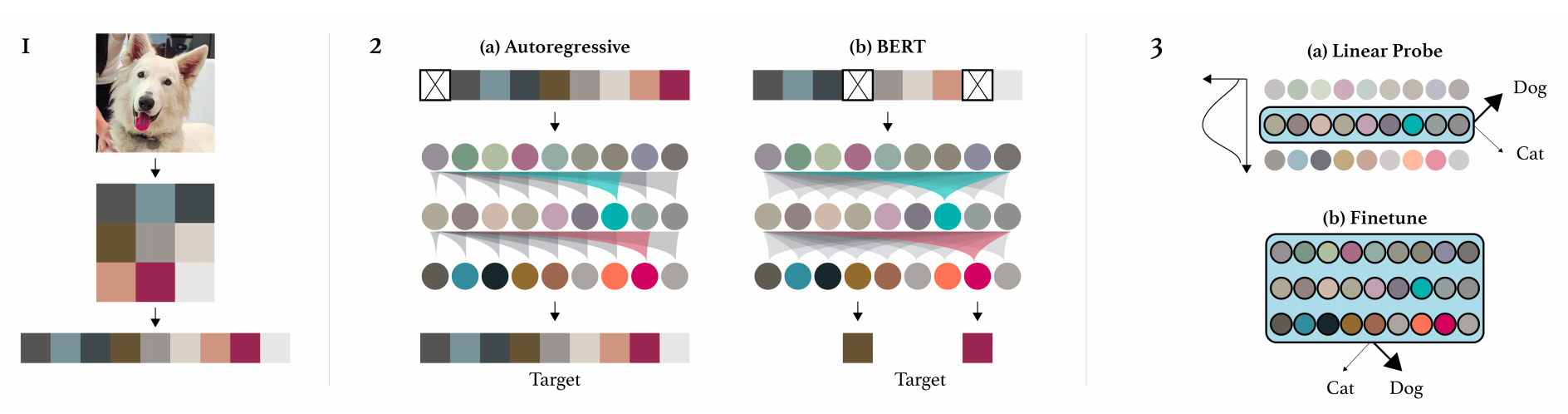
The architecture is the same as the language GPT model with decoder stacks one upon other. The only difference is in their model training approach their implementation of both
- Autoregressive training
- Masked image modelling training
 Picture courtsey: iGPT paper
Picture courtsey: iGPT paper
1. Downsampling the images 2. The two training methods 3. Evaluation strategies and in-depth linear probe analysis
Fitting Data in GPUs
The memory requirement of a transformer decoder scale quadratically with sentence length. It is tough enough to fit a language GPT model in single GPU these days, imagine what would happen in the case of a flattened ImageNet 224^2x3 image, even a single layer won’t fit in a GPU! The memory requirement is so huge that even OpenAI could not flex their GPU cluster so like a common (poor maybe? :P) DL researcher they downsample their input resolution to 48x48x3 or 32x32x3. Don’t get your hopes high, even then it is out of our purse to train such a model.
Performance evaluation and Linear Probe
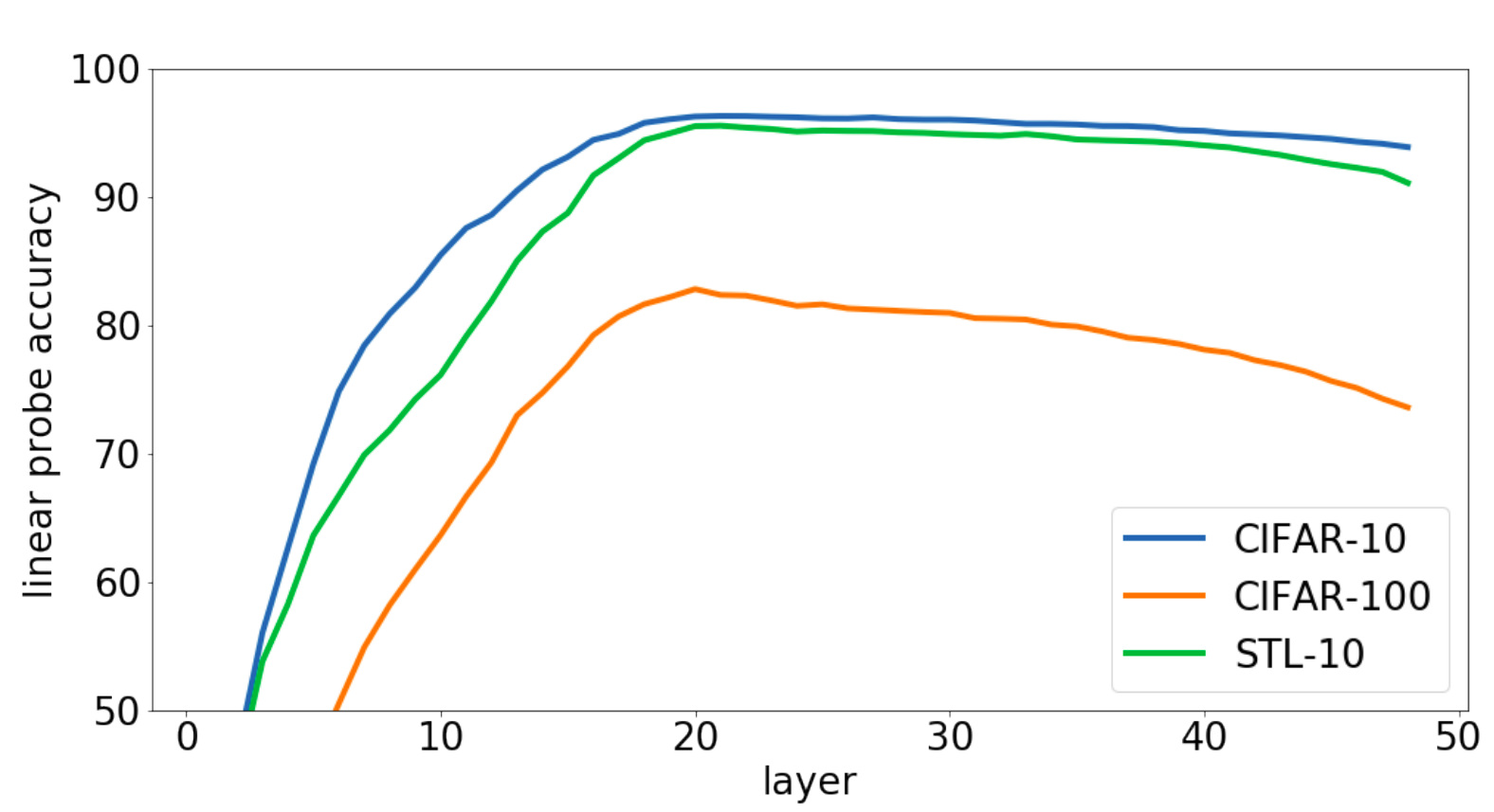
Quite admittedly, the iGPT works well in completing masked images and even in generating random images from scratch. Apart from that, the researchers tested iGPT on classification tasks by attaching a linear classification layer with iGPT. The position of attaching this linear layer is something that provides more insight into iGPT. They tied the linear head after various decoder stages in the model, something they term as the linear probe and found that the feature map at the middle layer is best suitable for the classification task. This might be due to the fact that initial decoder layers are just similar to a normal ConvNet learning local low-level features, the penultimate layers are trained towards predicting next pixel by using the learnt so far. It is the middle layers which would entail the best feature map of the input by comprehending the global information.
 Picture courtsey: iGPT paper
Picture courtsey: iGPT paper
Performance variation with respect to layer in Linear Probe. Notice the peak in performance irrespective of the dataset in the middle layer
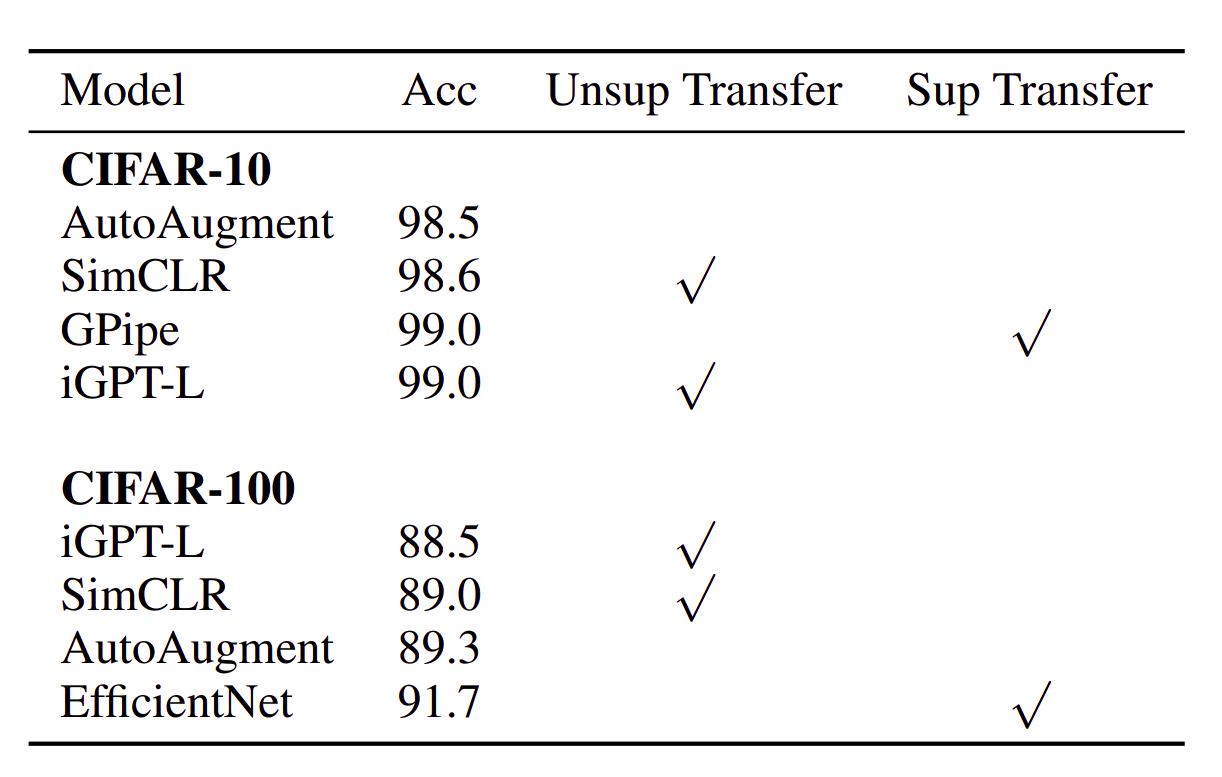
This fact gets more interesting when in full fine-tuning experiments, the authors claim that even after doing linear probing the model performs best when the classification head is at the end. This suggests that the pre-trained layers quickly adapt to the classification signals when gradients pass through them, making use of more depth and data structure retention capability of the deeper transformer models.
 Picture courtsey: iGPT paper
Picture courtsey: iGPT paper
Full fine-tuned performance of iGPT
Highlight and Takeaway
In sum, iGPT provides a great deal of insight into the learning done by each decoder layer. Till now, no solution has been found to satiate the data need of transformer models, something the authors report when iGPT fails to generalise CIFAR-10 with very limited data. Nevertheless keeping the data constraint aside, iGPT not only achieves comparably high numbers on complex datasets like ImageNet but it also reinforces the fact that transformers are soon going to revolutionalise DL models in all its subfields. All said, I am here as eager as always looking to learn more about their caveats.
Until then, Stay Well! Stay Safe!