 Picture courtsey: Pexels by Engin Akyurt
Picture courtsey: Pexels by Engin Akyurt
The transformer architecture is simply composed of stacked linear layers through which data is passing in a unique manner. The attention module consist of three separate neural nets named as Query, Key and Value combining the data in a yet again unique fashion. This naturally raises a question of what exactly is these Query, Key and Value matrices learning. We can't just take the name "Query" & "Key" and accept that the matrices are in actuality generating queries and keys. The paper "" digs deeper on this question and actually shows that the Query and Key matrices can safely be replaced by a gaussian sampler centered around each word while retaining the BLEU score on translation task! So, let’s start understand the paper Hard-Coded Gaussian Attention for Neural Machine Translation by Weiqiu You et al.
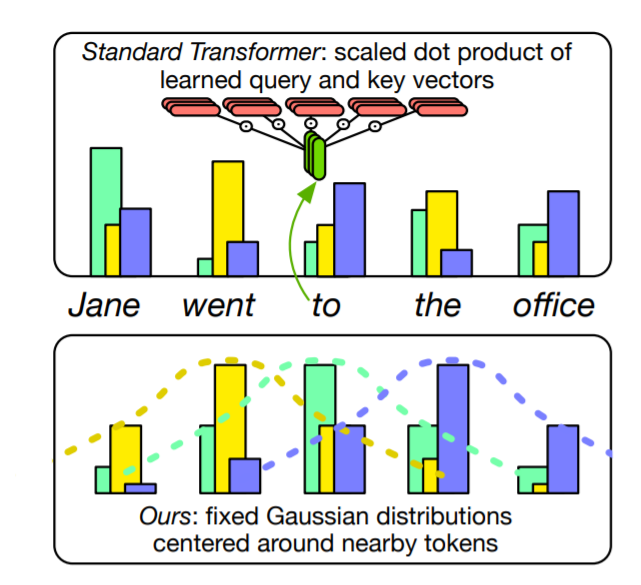
Picture and caption courtsey: Original paper
Three heads of learned self-attention (top)
as well as the hard-coded attention (bottom) given the
query word "to". Notice, each attention head is a
Gaussian distribution centered around a different token
within a local window
Architecture
The feed-forward architecture of transformers have speed up training by parallelising the timesteps but it is severly constrained in memory due to the large number of parameters in its architecture. The Hard-coded gaussian attention tried removing this dependency by challenging the learned information by the "Query" and "Key" matrices to the extreme. The paper replaces each attention head with a "hard-coded" standard normal distribution centered around a particular token in the sequence.
The intuition behind multi-headed attention (MHA) is that each head is supposed to model a different aspect of the language (eg. morphology, syntactic, syllables etc.) and get the information from every corner of the sequence. But the authors show that each head tend to focus only on just a window of one to two tokens around the current position with the encoder heads having the least variability. Thus, the attention heads were modified to have weight the embeddings from the "Value" matrix using a gaussian sampler. Concretely,
\begin{equation} Attn(i,\mathbf{V}) = \mathcal{N}(f(i), \sigma^2))\mathbf{V} \end{equation}Hard coding the attention heads in self-attention was easy but for cross-attention had some inherent problems. The queries and keys in cross attention are not derived from the same token representations rather, the queries come from the decoder while the keys come from the encoder. The authors tried two different methods in modelling cross-attention.
Hard-coded cross attention: For a target position i the gaussian were centered on positions [\gamma*i-1], [\gamma*i] and [\gamma*i+1] of the source sentence where \gamma the ratio of average source sentence length and target sentence length in the training set.
Learning a single cross attention head: Departing from the parameter approach, a single cross-attention learning head is included at the last decoding layer, rest all the attention heads are hard-coded.
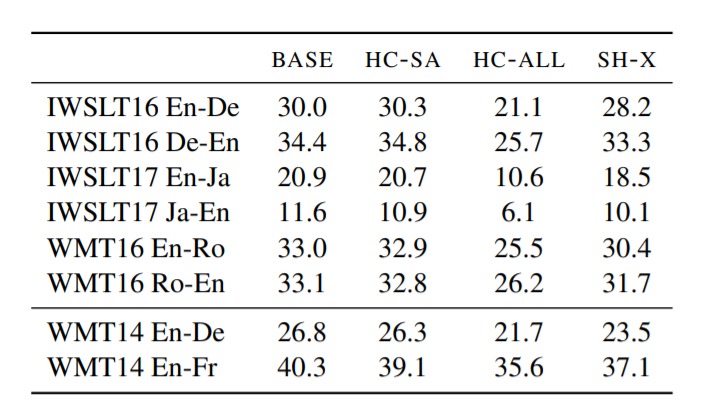
Picture courtsey: Original paper
BLEU Score of the approaches on six smaller datasets (top) and two larger datasets (bottom). Hardcoded self-attention (HC-SA); Harcoded all-attention (HC-All); BASE (Base transformer); SH-X (Only one cross attention)
Results
The results are suprisingly good. The hardcoded encoder-decoder attention with single learnded cross attention achieved almost equal BLEU score to the BASE transformer.
Moreover, this configuration allowed the model to fit 17% more tokens into a single batch, while also providing a 6% decoding speedup compared to BASE transformer on the larger architecture used for WMT16 En-Ro dataset.
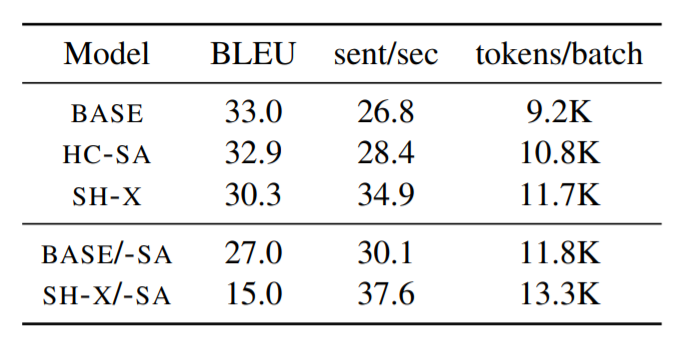
Picture courtsey: Original paper
Decoding speedup (in terms of sentences per
second) and memory improvements (max tokens per
batch) on WMT16 En-Ro for a variety of models.
The authors conjecture that feed-forward (FF) layers play a more important role in hardcoded self-attention than in BASE transformer by compensating for the loss of learned dynamic self-attention and uphold the performance. Nevertheless, it is exciting for me as a reader to see such fresh challenging ideas popping up in the field every quarter.
Until then, Stay Well! Stay Safe!