 Picture courtsey: ready made from Pexels
Picture courtsey: ready made from Pexels
Leonardo DiCaprio famously said in his Oscar speech, “The climate change is real!”. Looking at the compute used by recent DL papers, I would not be surprised if soon a study claims that GPUs have contributed to at least one-degree increase in temperature. Imagine running a cluster of 100 Nvidia GPUs continuously for months for just a meagre rise in SOTA and later realising that you missed saving your checkpoint (*oof*) ending up training everything again! Soon I believe that papers should be ranked on the ratio of the amount of CO2 they have contributed to the planet to the increase in their performance (if any bigshot researcher is reading this, please feel free to raise this point in your next conference :P). But realistically, transfer learning has been used in repurposing trained neural nets on different datasets, but can we do more? The paper Adversarial Reprogramming of Neural Networks by Gamaleldin et al. explores this niche.
 Picture courtsey: AdverTorch
Picture courtsey: AdverTorch
Targeted adversarial attacks can ridiculously fool neural networks
The advent of adversarial examples, where a perturbation of single pixel in an image can cause neural networks to confuse a chihuahua with a cupcake, has contributed to a widespread scepticism in the adoption of neural networks. But, there is also a positive side to it. The paper addresses the possibility of making adversarial perturbation on an existing dataset to make it usable on a model trained on a completely different dataset, creating a likelihood of reusability of a neural network, something which has not been explored enough. This paper shows that a single adversarial change in an entire dataset can also be a possible alternative for reusability of a pre-trained neural network.
Problem Notation
Given a model f trained to perform an original task with inputs x and an adversarial task with input x_{0} (size can be different from x) producing output g(x_{0}). The reprogramming then can be formalised as
\begin{equation} h_g( f(h_f(x_{0})) = g(x_{0}) \end{equation}
where x_0 is the adversarial image, g is the adversarial task, h_f is a function that resizes the small image x_0 to the size of x and adds the adversarial perturbation (this is the parameter which is learned), f is the original task, h_g is just the hardcoded mapping between the original labels and the adversarial labels to convert the outputs f(x) back to the domain of g(x_{0})
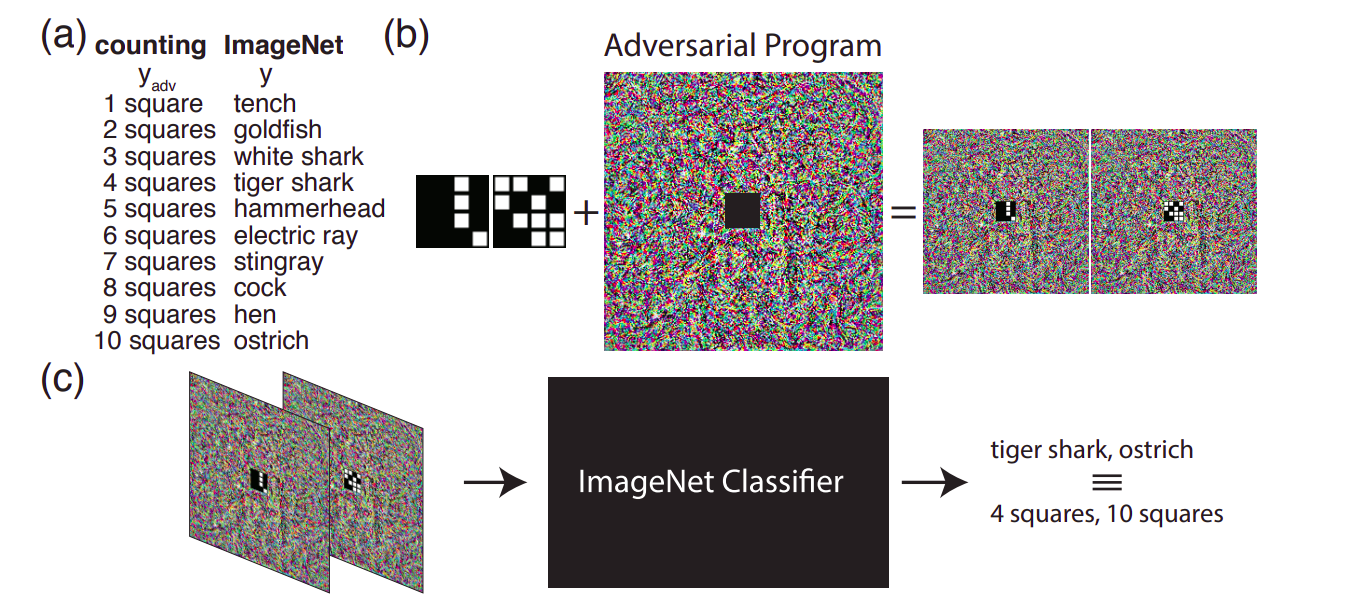 Picture courtsey: ARNN paper
Picture courtsey: ARNN paper
a) The hardcoded h_g for counting square task b) Perturbed image generated for ImageNet model c) Fooling ImageNet classifier in classifying our task
Method
In the paper, the author consider f to be an ImageNet model and g to be either MNIST or CIFAR-10 classification task. The only learnable parameter is a weight matrix W \epsilon R^{n * n * 3}, where n is the width of ImageNet images. The adversarial perturbation added to all images P is defined as
\begin{equation} P = tanh(W \odot M) \end{equation}
where M is a Mask matrix with 0 at the symmetrical central space of R^{ n_0 * n_0 * 3} and 1 elsewhere to accommodate the x_0. Then the adversarial input to f becomes,
\begin{equation}
h_f(x_0) = X_{adv} = x_0 + P
\end{equation}
Let P(y|x) be the probability that an ImageNet classifier gives to ImageNet labels y \epsilon \{1,2,..., 1000\}, given an input image x. The adversarial goal is thus to maximise the probability P(h_g(y_{adv})| X_{adv}) which the author formulates as the optimisation problem as
\begin{equation}
W = argmin_W(-log P(h_g(y_{adv})| X_{adv}) + \lambda ||W||^{2}_F
\end{equation}
The cost of the computation is minimal as the attacker is only supposed to store the weight W and leave the rest of the computation to the host program. Interestingly, there is no training involved in the weights of the ImageNet model.
 Picture courtsey: ARNN paper
Picture courtsey: ARNN paper
a,b) Limiting the pixels or perturbation does not cause much decrease in performance c) Fooling the ImageNet model while still retaining the visual aspect of the original ImageNet
Strengths
- The majority of previous adversarial attacks have been largely untargeted attacks, aiming just to degrade the performance of a model or targetted attacks where an attacker aims to produce a specific output for an input. This paper explores a new adversarial goal of re-purposing existing neural networks without forcing the original model to produce specific desired outputs in tasks that they were not intended to do initially
- The generated weights W are same for an adversarial dataset and model pair, giving further memory space advantage in saving and retrieving such a model Consequently, the training would be faster due to such small number of parameters compared to training a whole ImageNet model on MNIST specifically
- The authors in their ablation study shows that even after limiting perturbation to a mere 10%, they can retain the accuracy over the other dataset, depicting the robustness of their method
- The authors also show that their training method is robust against similarities between the original and adversarial data by shuffling the MNIST image pixels and still retaining the performance
Weaknesses and Possible solutions
- The authors only use simple datasets like MNIST and CIFAR-10 over orders of more complex ImageNet dataset pre-trained models. They should have tried their methodology over some recent complex datasets, like IMDB-Wiki dataset (100 classes). Alternatively, they could have tested their approach on an MNIST trained on VGG net with ImageNet dataset for assessing the robustness of their method
- The paper's appendix shows the compute required by them to train their model. Unexpectedly, the computation for training a single learnable parameter W is too high. This also undermines the robustness of the approach and feasibility of training such a W across different modalities
- The flexibility of a neural network for repurposing should have been discussed in more detail. The paper only compares randomly initialised model against the pre-trained model in their ability to train for the task. A section discussing partially-trained ImageNet models' ability to train for the adversarial task could have been added to further explore this point

Picture courtsey: Ripple effect group
Scope of Improvements or Further possible extensions
The authors only consider a single W for an adversarial dataset and model pair. In their ablation study, they depict that even after shuffling MNIST pixels (i.e., removing any semantic similarity between MNIST and ImageNet) they were able to train a W. Thus, it clearly hints a possibility of training a single W for both datasets like MNIST and CIFAR-10 as pixel structure is not affecting the adversarial task. Moreover, the hardcoded h_g for the two datasets could range from just first 10 labels to a larger subset of 1000 ImageNet labels. Hence, creating an opportunity to train a single perturbation W for potentially 100 datasets (with 10 classes each) for a single ImageNet model
Since, the paper informally shows that a W is present for every non-linear network. This adversarial reprogramming could be formulated on other modalities like NLP datasets too. If successful, a more interesting follow-up could be developing a single perturbation for two datasets from different modalities (say NLP and CV) over a single model, a One For All model, something researchers have been trying for a long time
Until then, Stay Well! Stay Safe!