 Picture courtsey: Marlene Leppänen from Pexels
Picture courtsey: Marlene Leppänen from Pexels
Recently ICLR 2020 concluded with its virtual conference and among the 687 papers that were present in the fabled conference, one particularly caught my eye, ELECTRA. In the previous article, I mentioned how the bigger models are winning the NLP battle but ELECTRA discriminative language model reinforced my belief that smarter brain can always beat bigger muscles (*cough* GPT-3).
In this post, I am covering the paper ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators other than a catchy name ELECTRA outperformed BERT and XLNet given the same model size, data and compute. ELECTRA-small (similar terminology as BERT) has 1/20th the parameters and requires 1/135th the pretraining compute than BERT-Large! Before diving further, if you are unsure about the differences between discriminative and generative models, I would suggest to you to read this blog post.
 Picture courtsey: ELECTRA paper
Picture courtsey: ELECTRA paper
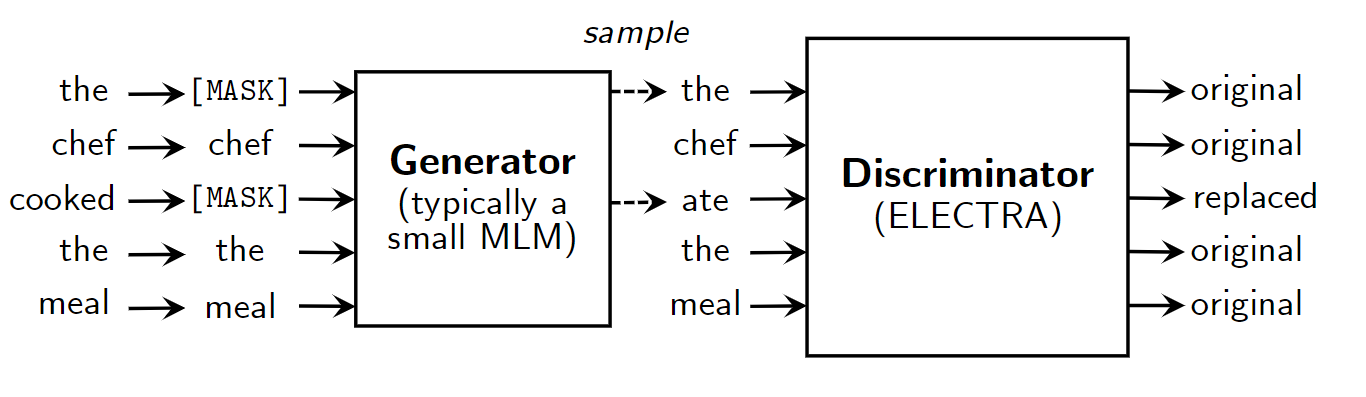
Overview of the model architecture
Architecture
Let's dive into the engine of the paper or rather its Architecture. ELECTRA trains two encoders, a generator G and discriminator D. Given an input sentence, the generator G randomly masks word in the sentence and replace them with [MASK]. Note that, the MLM of G randomly masks any words in the sentence whereas MLM of BERT and XLNet masks specific tokens in the sentence (15% of the vocabulary). The generator G then learns to predict the original identities of the masked-out tokens. On the other hand, the discriminator D tries to distinguish the fake/replaced tokens from the corrupted sentence generated by G.
The loss function of generator focusses solely on improving its MLM objective and discriminator on detecting replace tokens. Finally, the combined loss function of G and D is minimised over a large corpus of raw text.
 Picture courtsey: ELECTRA paper
Picture courtsey: ELECTRA paper
Loss function (Refer to the paper for symbolic meaning of each term)
To some computer vision folks, this might look like a GAN training structure but it is not. The backpropagation step cannot happen through discriminator to the generator because there is a sampling step (replacing the masked words from vocabulary) through which backpropagation cannot happen. It is also the reason why GAN has not been sufficiently applied in NLP. The authors tried to circumvent this issue by training the generator using reinforcement-learning but they claim that RL performed worse than this maximum-likelihood training.
Training the model
Dataset
The model was pre-trained on two sets of datasets:
- ELECTRA-base: 3.3B tokens from Wikipedia and Book Corpus (same dataset as BERT)
- ELECTRA-large: 33B tokens from Wikipedia, Book Corpus, ClueWeb, CommonCrawl and Gigaword (same dataset as XLNet)
Weight sharing
ELECTRA tied the embeddings of their generator and discriminator. According to the paper, ELECTRA benefits from tied token embeddings because MLM is effective in learning the embeddings better while discriminator only updates tokens that are provided to it by the generator which is less than the vocabulary, the generator's softmax over the vocabulary densely updates all tokens embeddings.
Training algorithm
The model was trained with a two-step training procedure:
- Train the generator for n steps improving its MLM loss, {\mathcal{L}_{MLM}}
- Initialise the weights of the discriminator with that of the generator (this is possible only if the generator and discriminator have the same size) and then train it for n steps keeping generator weights frozen while reducing {\mathcal{L}_{Disc}}.
 Picture courtsey: ELECTRA paper
Picture courtsey: ELECTRA paper
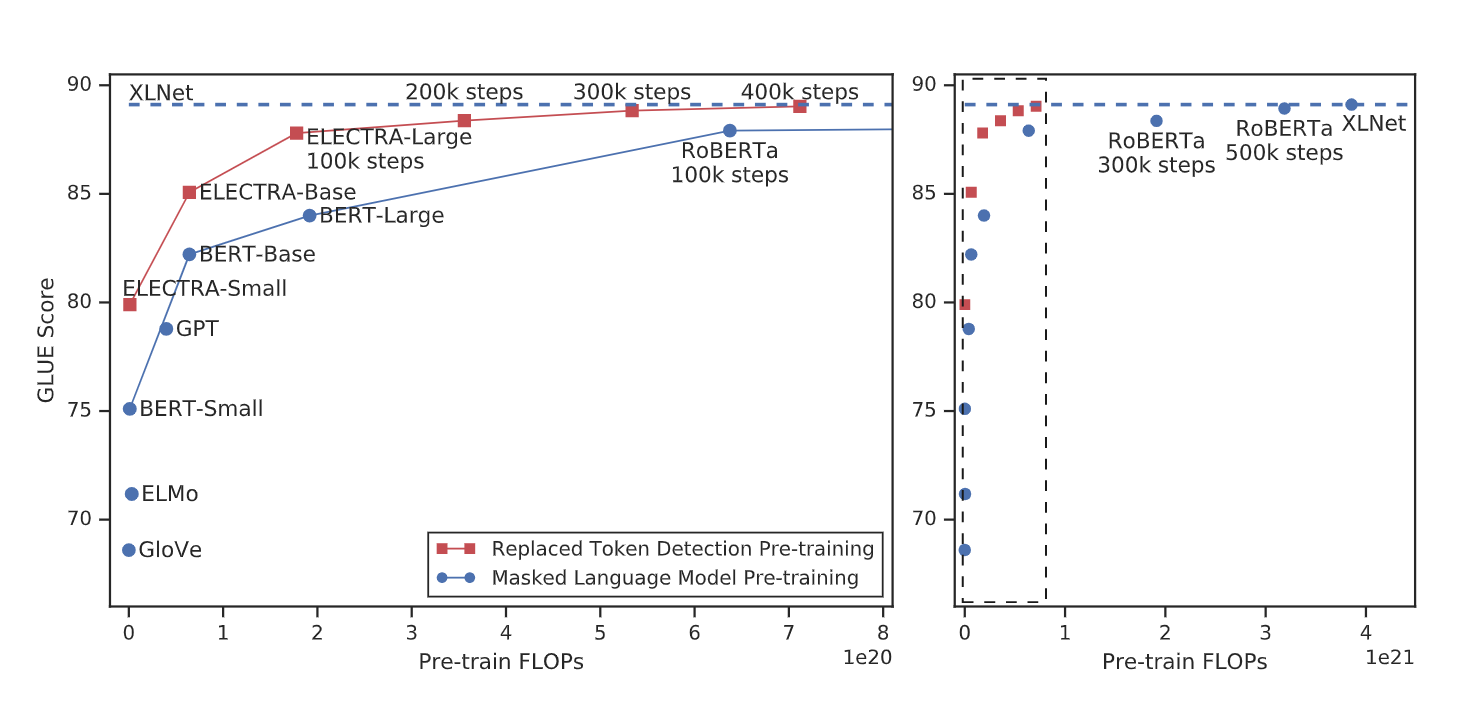
Performance on GLUE outperforming MLM based models with less compute. Left figure is a zoomed in version of right dashed box
Results
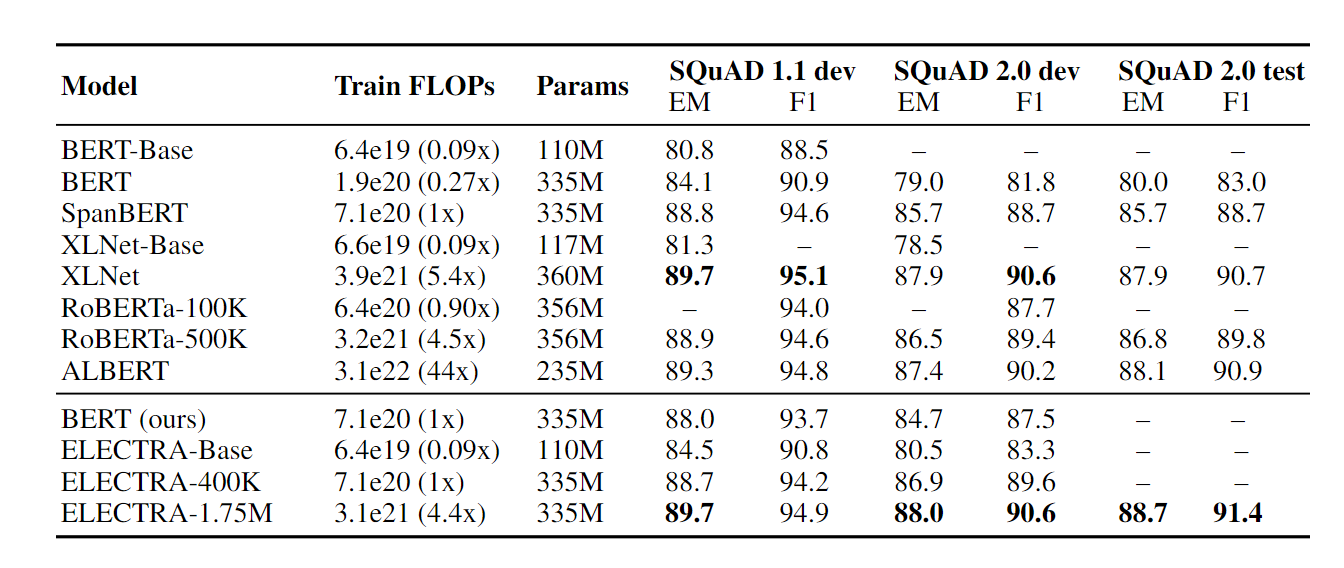
ELECTRA not only outperformed BERT by 5 point GLUE Score but is also highly compute efficient. In the Question-answering task, it outperformed previous models scoring higher than SQUAD 2.0 benchmark. This performance jump can be partly attributed to the ELECTRA's fake token detection being analogous to SQUAD 2.0 where a model needs to distinguish answerable questions from fake unanswerable questions.
 Picture courtsey: ELECTRA paper
Picture courtsey: ELECTRA paper
Performance on SQUAD 1.1 and 2.0
Highlight and Takeaway
Masked language modelling has been the backbone of the language models for quite some time. Its main drawback is that it is confined for only 15-20% of the tokens in the whole corpus. Hence, a large corpus is required to train such language models notably, BERT and XLNet. ELECTRA got away with this problem by employing a discriminative training regime where it would recognise corrupted tokens in the input. This resulted in faster training with less data, less compute and higher performance! What more could we ask for!? Let's hope more such papers make it to the community...
Until then, Stay Well! Stay Safe!